
Ce billet est le quatrième d’une série proposée par l’Abes afin d’accompagner les membres de ses réseaux dans la lecture du rapport Les implications pratiques de la Transition bibliographique dans les bibliothèques ESR du cabinet Pléiade Management & Consultancy.
Pourquoi les bibliothèques vont-elles vers le Linked data ?
Commençons par une définition du Linked data. Initiative du W3C – organisme international à but non lucratif qui définit les standards du Web – le Web de données (Linked data) vise à favoriser la publication de données structurées sur le Web, non sous forme de silos de données isolés les uns des autres, mais reliés entre eux afin de constituer un réseau global d’informations (source : article Web de données sur Wikipedia). Cette technologie favorise l’interopérabilité et la compréhension par les machines des ressources elles-mêmes comme de leurs relations.
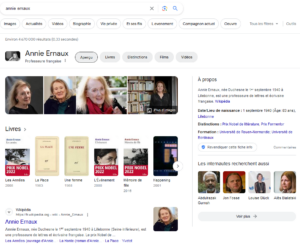
Rappelons que, depuis de nombreuses années, l’Abes s’est engagée dans l’exposition de ses données sur le Web de données. C’est de cette façon qu’on obtient des résultats issus du Sudoc en utilisant un moteur de recherche générique. De même, les données disponibles via les applications gérées par l’Abes (Sudoc, IdRef, Theses.fr, SciencePlus…) sont largement partagées et réutilisées dans le contexte du Web de données.
Que peut apporter le Web de données aux bibliothèques ?
Les bibliothèques voient dans le Web de données de nombreux avantages :
- relier les catalogues des bibliothèques avec les autres données du Web
- rendre les données des bibliothèques réutilisables par d’autres communautés, notamment celles du Web culturel et commercial
- accroître la visibilité des catalogues de bibliothèques par les moteurs de recherche et proposer des services supplémentaires comme, par exemple, la localisation d’une ressource dans la bibliothèque la plus proche
- faciliter la navigation au sein des données de manière souple et intuitive, notamment grâce aux nombreux liens entre les données mais aussi grâce aux interfaces de nouvelle génération
- tirer parti de la structuration des données présentes dans les catalogues et les référentiels, gage de haute qualité pour les données de bibliothèques
- faciliter et étendre les possibilités de partage de données entre bibliothèques
- donner la possibilité aux bibliothécaires de sortir de leur « niche technologique » en utilisant des technologies non spécialisées
Qu’est-ce qui empêche, aujourd’hui, les données des bibliothèques d’être sur le Web de données ?
Même si de nombreux catalogues de bibliothèques, dont le Sudoc, exposent leurs données en RDF, langage de base du Linked data, celles-ci, bien que correctement structurées et liées, ne sont cependant pas exploitables à leur plein potentiel dans l’univers du Web de données. En effet, les données suivent la logique des formats MARC, propres aux bibliothèques et à leurs besoins, et reposent sur des notions peu usitées en dehors du monde des bibliothèques, comme celle de notice bibliographique.
De fait, dans la majorité des cas, même si les pages HTML des catalogues sont liées entre elles, les données qu’elles contiennent ne le sont pas, restant ainsi dans le “Web profond”, peu visibles et peu accessibles par des machines, car inadaptées aux technologies du Web de données.
Comment favoriser l’émergence des données des bibliothèques sur le Web de données ?
Dans les années à venir, la transition bibliographique devrait permettre de :
- structurer les données selon un modèle de description unique, connu et interprétable par toutes les machines, faisant appel à des notions non spécifiques au monde des bibliothèques. C’est l’objectif poursuivi par l’adoption du modèle IFLA LRM.
- traduire les données restructurées en RDF, en utilisant des vocabulaires – ou “ontologies”- compatibles avec IFLA LRM (comme par exemple l’ontologie RDA-FR) ou avec d’autres modèles entités-relations comme BIBFRAME, qui sera présenté dans un prochain billet.
Lorsque les données des catalogues seront structurées selon le modèle IFLA LRM et diffusées en RDF, elles deviendront plus visibles, plus partageables, et mieux exploitables.
N’hésitez pas à réagir à ce billet, en déposant un commentaire !
En savoir plus
Consulter les billets Punktokomo à propos du Sudoc en RDF :
- https://punktokomo.abes.fr/2014/09/05/le-sudoc-en-rdf-du-nouveau-12
- https://punktokomo.abes.fr/2014/09/05/le-sudoc-en-rdf-du-nouveau-22
Consulter les articles parus dans Arabesques :