Rappelons qu’à la suite de la réunion du Comité stratégique bibliographique (CSB) du 18 octobre 2023, un communiqué conjoint de l’Abes et de la BnF a été publié sur le site Transition bibliographique, afin d’expliciter les stratégies des deux agences pour l’implémentation de la Transition bibliographique dans leurs systèmes respectifs, c’est à dire la capacité à produire et/ou à diffuser des données bibliographiques selon un modèle entités-relations.
Le communiqué confirmait notamment le fait que l’Abes et la BnF auraient un calendrier d’implémentation différent : la date prévisionnelle retenue par l’Abes dans le cadre de son projet de réinformatisation étant 2028, ceci déterminera naturellement la date à partir de laquelle il sera possible, pour les bibliothèques du réseau Sudoc et les autres acteurs intéressés, de récupérer des données conformes au modèle entités-relations.
Annoncée dès 2023 en avant-première dans un précédent billet, une journée des utilisateurs d’UNIMARC va avoir lieu le 12 novembre 2024 à Maribor (Slovénie) et en ligne.
Ce type d’événement est organisé régulièrement par le PUC (Permanent UNIMARC Committee, IFLA) depuis plus de 20 ans, et s’est tenu pour la dernière fois à Téhéran (Iran) en 2018. Depuis, la communauté UNIMARC n’a pas eu d’occasion de se trouver physiquement réunie. Il y a évidemment les réunions annuelles du PUC, mais celles-ci ne regroupent que les quelques experts chargés de la maintenance du format, et non l’ensemble de ses utilisateurs. De plus, depuis la pandémie de Covid-19, elles ne se sont déroulées qu’en visioconférence.
À la demande de la BULAC, l’Abes a proposé aux catalogueurs signalant, régulièrement ou occasionnellement, des ouvrages en langue arabe, de se réunir afin d’échanger sur les spécificités liées à ce type de signalement.
Il s’agissait d’évoquer à la fois les contraintes techniques imposées par les outils de production et de consultation fournis par l’Abes pour chacun des réseaux (WiniBW, IdRef et Calames Pro), de traiter collectivement des questions de catalogage puis de réfléchir ensemble à des collaborations, afin de réunir les forces et les compétences particulières demandées par ce type de catalogage.
Après avoir sondé les membres des réseaux Sudoc, IdRef et Calames potentiellement intéressés, l’Abes a réuni une quarantaine de participants, sur un mode hybride (en présentiel à la BULAC, à distance via Zoom) le mardi 28 novembre 2023.
Les contraintes techniques pour les écritures sinistroverses et pour l’arabe en particulier
L’ arabe fait partie des écritures qui s’écrivent de droite à gauche, ce qui peut poser de réels problèmes pour le catalogage avec certains outils informatiques en Europe : dans une notice UNIMARC saisie avec WinIBW doivent cohabiter des sous-zones dans lesquelles les caractères sont saisis selon deux sens différents.
Où placer le caractère d’indexation @ ? Comment bien positionner le curseur ? À ces contraintes s’ajoutent celles de la saisie dans deux alphabets, qui impose souvent l’utilisation d’un clavier virtuel. Enfin, comment faire pour que les requêtes fournissent aux usagers, professionnels ou non, des résultats pertinents, alors que de nombreuses graphies sont possibles pour le même mot en arabe ?
La première partie de la réunion a donc été consacrée au relevé de ces problèmes techniques, dans les outils de production et de consultation actuellement proposés par l’Abes ainsi qu’au partage des astuces et solutions de contournement trouvées par certains collègues.
Comment le rapport van der Graaf a-t-il nourri les réflexions de l’Abes ?
La commande d’un rapport sur les implications concrètes de la Transition bibliographique dans l’ESR constituait la première réponse de l’Abes aux demandes formulées en 2022 tant par le Ministère de l’enseignement supérieur et de la recherche que par l’Hcéres dans son rapport d’évaluation de l’Abes, qui exprimaient tous deux la nécessité que l’agence clarifie sa trajectoire vers la transition bibliographique.
L’Abes s’est approprié les éléments fournis par le rapport de Mauritz van des Graaf dans le cadre de sa réflexion sur son Projet d’établissement 2024-2028, et les a également portés au niveau national, pour discussion au sein du Comité stratégique bibliographique (CSB), qui chapeaute le programme Transition bibliographique.
Le projet d’établissement 2024-2028 de l’Abes prend en compte l’importance du renouvellement technologique en œuvre à l’échelle internationale. S’il place en toute première priorité – et sur un temps long – la refonte du système de gestion des métadonnées de l’Abes (le Sudoc et ses applications satellites) du fait de son obsolescence technique et prévoit un investissement important pour mener à bien ce projet, des réalisations concrètes à moyen terme auront bien lieu, avec acquis progressif :
un premier déploiement du nouveau système remplaçant l’interface professionnelle de catalogage WinIBW et l’interface publique du Sudoc (PSI) en 2027
une interface expérimentale de visualisation des entités et relations issues du Sudoc également avant la fin de la période, quel que soit le modèle conceptuel qui sous-tendra les données dans le nouveau système de gestion
Cette façon de faire devrait permettre de s’adapter, au fil des années, aux évolutions en cours dans le paysage des standards comme dans celui des SGB, et d’en tirer le meilleur parti.
Parmi les suites du rapport de Maurits Van Der Graaf, une discussion nationale a eu lieu le 18 octobre, dans le cadre du Comité stratégique bibliographique (CSB). Il s’agissait de tirer les conclusions de l’analyse présentée dans le rapport pour la trajectoire du programme national Transition bibliographique.
Établie en 2014 autour de la nécessité de développer RDA-FR en tant que code de catalogage national et de sensibiliser la communauté documentaire aux enjeux associés à la modélisation entités-relations, la feuille de route initiale du programme n’avait jamais connu d’actualisation. Dans les faits, depuis 2014, cette trajectoire nationale s’est fixée sur un double principe :
le remplacement des normes de catalogage anciennes (AFNOR Z44-…) par le standard RDA-FR basé sur le modèle entités-relations international IFLA LRM
l’adaptation du format d’échange de données national, d’UNIMARC vers UNIMARC entités-relations.
Le rapport de Maurits Van Der Graaf fait apparaître, en creux, certaines limites que pose cette trajectoire pour l’écosystème de l’ESR, très fortement dépendant des développements internationaux en ce qui concerne, d’une part, le marché des logiciels documentaires utilisés par les établissements (SGB, outils de découverte, etc.) et, d’autre part, les flux de données que l’Abes met à disposition des réseaux de catalogueurs pour faciliter la description des ressources dans le Sudoc.
BIBFRAME (de l’anglais Bibliographic Framework) est à la fois un modèle de données de description bibliographique, un format et un vocabulaire. Il a été conçu par la Bibliothèque du Congrès pour remplacer le format MARC en se basant sur le Web de données afin de rendre les bases de données bibliographiques plus accessibles aux usagers, aussi bien dans que hors les murs des bibliothèques. (source : page Wikipédia Bibliographic Framework)
De MARC à BIBFRAME
En 2012, à la suite d’un rapport interne (paru 4 ans plus tôt) sur le futur du catalogage, qui constatait l’obsolescence technologique du MARC et son usage restreint à la communauté des bibliothèques, la Bibliothèque du Congrès développe avec le prestataire Zepheira un modèle de description et un vocabulaire basé sur le standard RDF. Cette initiative, appelée BIBFRAME, permet de décrire les ressources des bibliothèques en respectant des principes également promus par le modèle FRBR de l’IFLA (qui deviendra IFLA LRM en 2017) :
distinguer le contenu conceptuel d’un document, et sa matérialisation physique ou numérique
identifier les entités permettant de décrire la ressource et de la contextualiser (par exemple, les agents, les sujets)
relier les entités entre elles en utilisant leurs identifiants contrôlés.
à noter : Si ces principes étaient déjà présents dans le MARC21 (et à plus forte raison dans l’UNIMARC), ils étaient considérés comme l’exception dans les pratiques de catalogage, et non comme la norme (source : BIBFRAME Frequently asked questions).
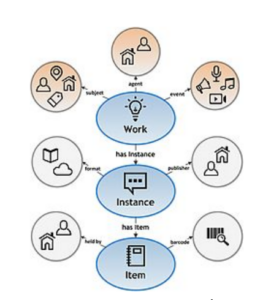
Le modèle BIBFRAME comprend 3 entités principales :
Work : il s’agit de l’essence conceptuelle d’une ressource (auteurs, langues, sujets)
Instance : elle reflète l’incarnation matérielle d’une ressource (éditeur, date de publication, format).
Item : il s’agit d’une copie réelle (physique ou électronique) d’une instance (localisation physique ou virtuelle, cote, code-barres).
BIBFRAME 2.0 (2016) : schéma conceptuel
Bien que l’on puisse considérer que le niveau “Work” dans BIBFRAME (bf:Work) est proche de l’entité “Expression” dans IFLA LRM, celles et ceux qui connaissent le modèle IFLA LRM voient tout de suite que ces deux modèles ne semblent pas compatibles. Certains établissements ayant implémenté BIBFRAME ont donc travaillé sur un niveau supplémentaire, le “Hub” (bf:Hub), qui correspond peu ou proue à l’entité “Oeuvre” du modèle IFLA LRM. Cependant, ces alignements ne sont pas si simples et la communauté BIBFRAME continue de travailler sur l’articulation entre les modèles BIBFRAME et LRM, qui est un modèle international publié sous l’égide de l’IFLA, ce que n’est pas BIBFRAME.
Pourquoi les bibliothèques vont-elles vers le Linked data ?
Commençons par une définition du Linked data. Initiative du W3C – organisme international à but non lucratif qui définit les standards du Web – le Web de données (Linked data) vise à favoriser la publication de données structurées sur le Web, non sous forme de silos de données isolés les uns des autres, mais reliés entre eux afin de constituer un réseau global d’informations (source : article Web de données sur Wikipedia). Cette technologie favorise l’interopérabilité et la compréhension par les machines des ressources elles-mêmes comme de leurs relations.
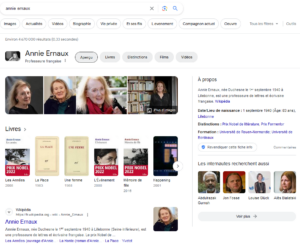
Résultats d’une recherche dans Google à propos d’Annie Ernaux : les données, de nature différente (biographiques, bibliographiques, iconographiques), sont reliées entre elles et agrégées pour construire la page de résultats
Rappelons que, depuis de nombreuses années, l’Abes s’est engagée dans l’exposition de ses données sur le Web de données. C’est de cette façon qu’on obtient des résultats issus du Sudoc en utilisant un moteur de recherche générique. De même, les données disponibles via les applications gérées par l’Abes (Sudoc, IdRef, Theses.fr, SciencePlus…) sont largement partagées et réutilisées dans le contexte du Web de données.
Que peut apporter le Web de données aux bibliothèques ?
Les bibliothèques voient dans le Web de données de nombreux avantages :
relier les catalogues des bibliothèques avec les autres données du Web
rendre les données des bibliothèques réutilisables par d’autres communautés, notamment celles du Web culturel et commercial
accroître la visibilité des catalogues de bibliothèques par les moteurs de recherche et proposer des services supplémentaires comme, par exemple, la localisation d’une ressource dans la bibliothèque la plus proche
faciliter la navigation au sein des données de manière souple et intuitive, notamment grâce aux nombreux liens entre les données mais aussi grâce aux interfaces de nouvelle génération
tirer parti de la structuration des données présentes dans les catalogues et les référentiels, gage de haute qualité pour les données de bibliothèques
faciliter et étendre les possibilités de partage de données entre bibliothèques
donner la possibilité aux bibliothécaires de sortir de leur « niche technologique » en utilisant des technologies non spécialisées
Modèle, code, norme et format … Et si on s’expliquait ?
Pour bien comprendre ce dont on parle lorsqu’on évoque la transition bibliographique, il faut bien connaître les différents concepts. Ce billet propose :
une définition des concepts suivants : “modèle conceptuel”, « norme”, “code de catalogage” et “format”
la description des liens qui existent entre eux.
Qu’est ce qu’un modèle conceptuel, une norme, un code de catalogage ?
Avant de définir ces concepts, faisons un parallèle avec un exemple que tout le monde connaît : le jeu de tennis.
Djokovic au service (source : Mad Ball from Flickr)
Si trois personnes devaient expliquer à une quatrième ce qu’est le tennis, la première personne pourrait commencer par dire : “Le tennis est un sport, qui consiste à se renvoyer une balle, entre deux joueurs, et à inciter l’adversaire à commettre une faute, pour emporter le point”
Puis, la deuxième pourrait préciser : “ On y joue sur un terrain qui s’appelle un “court”, il est rectangulaire, il mesure 23,77 m. de longueur pour 8,23 m. de largeur. La dimension de la balle doit avoir un diamètre compris entre 6,35 et 6.66 cm”.
Enfin, la troisième pourrait ajouter : “Si la balle atterrit hors des limites du court, le point est perdu ; si la balle touche le filet lors du service, on rejoue” .
À elles trois, ces personnes ont décrit le même sport, chacune sous des angles différents, mais complémentaires. La première personne a donné la définition, unique et universelle, du jeu de tennis. Partout dans le monde, cette définition s’applique. C’est un modèle conceptuel. La deuxième personne a donné des éléments techniques et pratiques à respecter pour que le jeu se joue de façon identique, partout et tout le temps. Ce sont des normes. La troisième personne a détaillé comment, dans le cadre de la définition donnée et au moyen des éléments techniques à respecter, chacun doit se comporter. Ce sont les règles du jeu, autrement dit le code.
Ce billet est le deuxième d’une série proposée par l’Abes, destinée à accompagner les membres de ses réseaux dans la lecture du rapport « Les implications pratiques de la Transition bibliographique dans les bibliothèques ESR » du cabinet Pléiade Management & Consultancy.
Pourquoi la France est-elle moteur dans le développement du format UNIMARC pour le catalogage d’entités et de relations ?
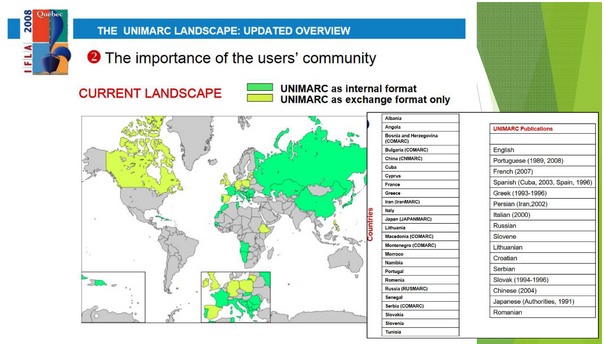
L’UNIMARC dans le monde
Le format UNIMARC (Universal Machine-Readable Cataloguing) est l’un des formats de la famille MARC, créé vers 1975 à partir du format MARC21 conçu par la Library of Congress. Considéré à l’origine comme un format d’échange de données bibliographiques, le format UNIMARC s’est ensuite développé comme format de production de données. Il est aujourd’hui le seul format MARC maintenu au sein de l’IFLA, par le Permanent UNIMARC Committee. Le dernier état disponible des pays utilisateurs du format UNIMARC date de 2008. (attention : la carte ci-dessous est indicative mais certaines informations sont obsolètes).
Source : Cordeiro, Maria Inês. The UNIMARC Landscape, updated overview. Présentation au congrès IFLA, 2008. Accessible en ligne : https://archive.ifla.org/VI/8/unimarc-survey-2008_results.pdf
Bien que l’usage du format MARC21 soit aujourd’hui largement dominant dans le paysage international, l’UNIMARC continue à être utilisé par un grand nombre de pays et institutions, et poursuit son développement, grâce aux experts membres du Permanent UNIMARC Committee, issus de différents pays : la Slovénie (qui assure la présidence du Comité), la Croatie, la Grèce, l’Indonésie, l’Iran, le Portugal, la Russie, la Roumanie, et la France, mais également un représentant de la société OCLC. Le format MARC21 est, lui, principalement maintenu par la Library of Congress américaine, mais le Royaume-Uni, le Canada et l’Allemagne sont également membres du MARC Advisory Committee (MAC), qui maintient ce format.
L’UNIMARC est en France le format d’échanges de données le plus répandu. Si un décret de 1993 l’a rendu obligatoire pour les bibliothèques de lecture publique, c’est également le format le plus utilisé dans les échanges de données (ou “transferts réguliers”) entre le Sudoc et les systèmes des bibliothèques de l’ESR, même si 10 établissements (sur les 152 membres du réseaux Sudoc) ont actuellement un SGB conçu pour le format MARC21. L’Abes diffuse ses données dans les deux formats, au gré des besoins des établissements de son réseau.
La transition bibliographique en France partage un objectif commun avec de nombreux autres pays, à savoir la restructuration des données conformément au modèle conceptuel de données IFLA LRM (Library Reference Model), maintenu par l’IFLA depuis 2017 et largement adopté par la communauté documentaire internationale. La particularité française réside dans le fait qu’elle a choisi de rédiger son propre code de catalogage, ‘RDA-FR’, en s’inspirant largement du standard international RDA conçu à cet effet.
En 2012, le rapport d’orientation remis au Comité Stratégique Bibliographique (CSB) – instance qui définit la politique nationale en matière d’information bibliographique – avait en effet clairement identifié certaines limites du code de catalogage RDA. Il relevait notamment une interprétation particulière du modèle FRBR, prédécesseur du modèle IFLA LRM. De plus, malgré sa revendication d’être un code à vocation « internationale », son inspiration était marquée par les règles de catalogage américaines (les AACR2), ce qui représentait un véritable changement de culture pour les bibliothécaires français.
En 2014, en réponse à ces constats, la France lance officiellement le programme national « Transition bibliographique ». L’une des démarches, confiée au groupe de travail dédié la normalisation, est l’élaboration du code ‘RDA-FR’, adaptation du code RDA au contexte français, avec une attention rigoureuse aux pratiques de signalement françaises, venant des règles internationales définies par l’ISBD.
En 2019, le code de catalogage international RDA est révisé en profondeur et largement restructuré pour devenir une bibliothèque d’éléments beaucoup plus générique. Après étude de cette version, la France rend un nouveau rapport faisant le constat suivant : malgré la résolution de nombreuses divergences initiales, des différences structurelles importantes persistent, notamment ce qui concerne le traitement de certains types de ressources. En conséquence, le rapport recommande de poursuivre la rédaction du code ‘RDA-FR’.
En poursuivant votre navigation, vous acceptez le dépôt de cookies tiers destinés à vous proposer des vidéos, des boutons de partage et des remontées de contenus de plateformes sociales.
 Rappelons qu’à la suite de la réunion du Comité stratégique bibliographique (CSB) du 18 octobre 2023, un communiqué conjoint de l’Abes et de la BnF a été publié sur le site Transition bibliographique, afin d’expliciter les stratégies des deux agences pour l’implémentation de la Transition bibliographique dans leurs systèmes respectifs, c’est à dire la capacité à produire et/ou à diffuser des données bibliographiques selon un modèle entités-relations.
Rappelons qu’à la suite de la réunion du Comité stratégique bibliographique (CSB) du 18 octobre 2023, un communiqué conjoint de l’Abes et de la BnF a été publié sur le site Transition bibliographique, afin d’expliciter les stratégies des deux agences pour l’implémentation de la Transition bibliographique dans leurs systèmes respectifs, c’est à dire la capacité à produire et/ou à diffuser des données bibliographiques selon un modèle entités-relations. À la demande de la BULAC, l’Abes a proposé aux catalogueurs signalant, régulièrement ou occasionnellement, des ouvrages en langue arabe, de se réunir afin d’échanger sur les spécificités liées à ce type de signalement.
À la demande de la BULAC, l’Abes a proposé aux catalogueurs signalant, régulièrement ou occasionnellement, des ouvrages en langue arabe, de se réunir afin d’échanger sur les spécificités liées à ce type de signalement.