

Billet précédent :
1. Les règles du jeu
Le score
1000 notices de monographies ont finalement été examinées par « le onze abesien ». Le jeu de données clusterisées par les testeurs a été confronté aux regroupements réalisés par l’algorithme dans la base de test. Les clusters ont été classés en six catégories une fois le taux de regroupement global connu :
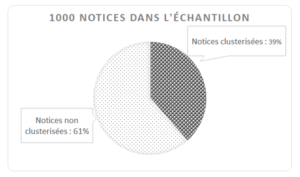
Parmi ces 1000 notices faisant partie du périmètre d’action du programme :
- 629 notices ne sont ni dans un cluster humain ni dans un cluster machine
- 371 notices font partie d’un regroupement humain et/ou machine.
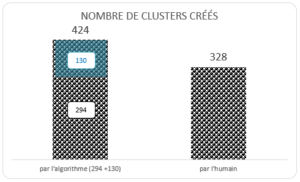
- 424 regroupements ont été créés par l’algorithme : 294 comprenant une des notices de l’échantillon et 130 clusters supplémentaires.
A noter : le total de 424 tient compte des 130 clusters machine qui apparaissent via les notices regroupées par les testeurs et qui ne font pas partie de l’échantillon de départ car l’algorithme est parfois contraint de créer plusieurs clusters là où l’humain n’en fera qu’un seul.
- 328 regroupements ont été créés par l’humain.
Un programme de traitement automatisé des résultats
Pour évaluer les résultats de l’algorithme OCLC, un programme léger (développé en interne) a comparé et classé les clusters réalisés par les humains avec ceux de l’algorithme. Les données des clusters, préalablement chargées dans une base Oracle, ont ainsi été traitées selon des spécifications précises dégageant six cas de figure.
Quelques chiffres
Rappel : le grand principe retenu pour l’expérimentation est d’obtenir des grappes de notices bibliographiques cohérentes, quitte à créer moins de grappes ou plus de petites grappes sans entités mêlées.
Pour y parvenir les paramétrages de l’algorithme ont volontairement été durcis afin d’éviter au maximum les regroupements abusifs.
Environ 70% des regroupements effectués par la machine répondent aux principes retenus pour la seconde expérimentation.
Les cas où l’algorithme respecte le principe édicté
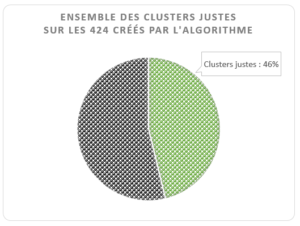
L’algorithme et l’humain obtiennent le même résultat
L’algorithme et l’humain s’accordent pour créer le même regroupement dans 174 cas sur les 424 clusters créés par la machine (41%).
De par ses contraintes techniques, l’algorithme obtient le même résultat que l’humain en créant plusieurs clusters dans 22 cas sur les 424 (5,2%).
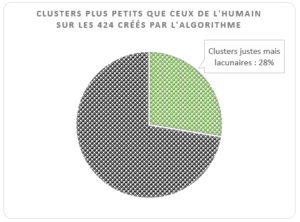
L’algorithme regroupe moins de notices que l’humain
L’algorithme ne réussit pas à regrouper toutes les notices que l’humain a rassemblées dans 117 cas sur 424 (27,6%).
L’algorithme aurait dû créer un cluster
L’algorithme ne crée pas de cluster alors que l’humain le fait à partir de 43 notices de l’échantillon. Les restrictions de paramétrages et/ou la qualité des notices sont en cause.
Les cas où l’algorithme ne respecte pas le principe édicté
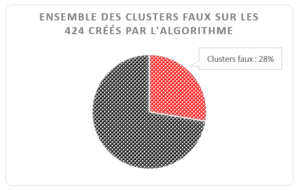
Le programme crée des clusters faux dans 74 cas sur 424 (17,4%) car il ne rassemble pas les mêmes notices que l’humain.
Enfin, il crée des clusters à tort, là où l’humain ne le fait pas, dans 43 cas sur 424 (10%).
A suivre…
Ping : Expérimentation Sudoc FRBR II. L’évaluation : algo vs humain. 1/3 - OuBiPo
Ping : Expérimentation Sudoc FRBR II. L’évaluation : algo vs humain 3/3 - OuBiPo
Ping : Veille 2020 - T4 - logiciels libres en bibliothèque, pratiques et actualité - BibLibre - Services et logiciels libres pour les bibliothèques - SIGB Koha, portail Bokeh, numérique, gestion