
L’évaluation globale de l’expérimentation annoncée dans le billet précédent a pu s’achever à la fin du mois de juin avec deux mois de retard sur le calendrier initial.
Les forces et les faiblesses de l’algorithme sont désormais connues :
Les paramétrages actuels permettent de traiter au niveau œuvre une partie non négligeable des notices de monographies qui représentent le plus gros volume des données du Sudoc. Cependant, le nombre total de notices regroupées reste modeste par rapport au périmètre pris en compte par le programme (un grand nombre « d’unicas » d’œuvres en sont aussi responsables). Par ailleurs, l’algorithme ne tourne pas sur toutes les données du Sudoc (notamment les agrégats dont font partie les ressources continues) et l’hétérogénéité des pratiques de signalement ainsi que la qualité des notices limitent ses performances.

Voici une présentation de cette évaluation publiée en trois parties :
- Les règles du jeu (ce billet)
- Le score
- L’analyse des résultats du match
Les règles du jeu
Les objectifs de l’évaluation
D’une part, il s’agissait de mieux évaluer le périmètre de données que ce programme peut traiter correctement dans le Sudoc (hors problème de catalogage) et de mesurer ce qu’il faudra traiter d’une autre façon. D’autre part, il était important de détecter les anomalies récurrentes dues au catalogage pour pouvoir améliorer la qualité des données et par rebond, les performances de l’algorithme.
Le nombre total de notices du Sudoc prises en compte par l’algorithme avoisine les 13 millions mais un peu plus d’un quart seulement sont clusterisées (environ 3,4 millions de notices bibliographiques pour 1,3 millions de clusters).

La méthode
Des tests à l’aveugle sur un échantillon représentatif de notices du Sudoc ont été mis en place. Le principe était de mesurer la pertinence des résultats du programme par rapport aux regroupements effectués par un humain, en partant du postulat que l’humain a toujours raison.
L’échantillon
Un peu plus de 1000 notices bibliographiques localisées ont été sélectionnées en respectant plusieurs critères :
- assurer une représentation proportionnelle de chaque type de document traité par l’algorithme
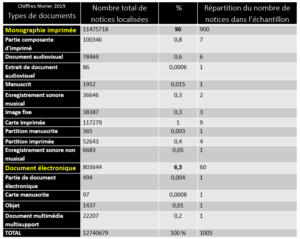
- refléter autant que possible l’historique de catalogage dans le Sudoc par une sélection de PPN (numéro d’identification unique de notice dans le Sudoc attribué par incrémentation) réalisée par ordre croissant à intervalles réguliers afin de balayer la base par strates
- tenir compte des 100 éditeurs les plus représentés dans le Sudoc en vérifiant leur présence dans au moins une notice de l’échantillon
- s’assurer également que les thèses étaient bien représentées. 35 notices de thèses ont été ajoutées au lot de notices retenues.
Les tests
Au départ, une série de tests avec des membres du réseau Sudoc avait été prévue. Ce volet plus expérimental devait servir les travaux de normalisation en cours sur des ressources particulières comme les documents cartographiques ou musicaux, les images animées ou fixes (ce qui aurait été l’occasion de balayer plus de notices pour ces documents). Hélas, le printemps confiné n’a pas permis de maintenir ces séances de tests. C’est donc sur le seul corpus des monographies représentant tout de même près de 97% des données traitées par l’algorithme que l’Abes s’est concentrée.
Dans une base de test dédiée, onze bibliothécaires de l’Abes ont créé, via l’interface professionnelle de catalogage WinIBW, des clusters de notices de monographies à partir de PPN de l’échantillon constitué pour l’exercice. Pour chaque PPN, les testeurs ont créé un cluster quand cela était possible en recherchant dans la base des notices représentant la même œuvre tout en respectant certaines règles de regroupements. Ces règles pouvaient être différentes de celles de l’algorithme pour laisser l’humain libre de ses choix là où des paramétrages techniques pouvaient être plus restrictifs pour l’algorithme compte tenu de la structuration des données. Les variations de traitement des ressources cataloguées sont autant de contraintes fortes pour l’algorithme alors qu’un humain peut passer outre.
Exemples de traitements de titres d’ouvrages pour lesquels l’humain crée un cluster alors que l’algorithme ne peut pas
Pour l’algorithme le titre de l’œuvre correspond aux chaînes de caractères de couleur orange.
Voici deux exemples où l’algorithme ne peut pas réaliser le regroupement des notices 1 et 2 car il est limité par ses paramétrages.
Catalogage avec ou sans complément de titre
Les paramétrages prennent en compte le complément de titre comme faisant partie intégrante du titre au niveau de l’œuvre. Par contre les zones de notes ne peuvent être exploitées par le programme et seul l’humain peut faire un rapprochement pour ces deux notices.
Notice 1 : avec complément de titre (présence d’une sous-zone $e)
200 1#$aLes @provençalistes du XVIIIe siècle$elettres inédites de Sainte-Palaye, Mazaugues, Caumont, La Bastie, etc.$fpar J. Bauquier
Notice 2 : sans complément de titre mais une zone de note sur l’édition et l’histoire bibliographique
200 1#$aLes @provençalistes du XVIIIe siècle$fJ. Bauquier
305 ##$aSous-titre de l’édition originale : Lettres inédites de Sainte-Palaye, Mazaugues, Caumont, La Bastie, etc.
Complément de titre ou titre de sous-partie
Le numéro et le titre de sous-partie (sous-zones $h et $i) ne sont pas pris en compte par l’algorithme au niveau de l’œuvre car ils sont d’un niveau de granularité interne à une même œuvre.
Notice 1 : avec deux compléments de titre pris en compte au niveau de l’œuvre
200 1#$aL’@évolution des genres dans l’histoire de la littérature$eintroduction$el’évolution de la critique depuis la Renaissance jusqu’à nos jours$fFerdinand Brunetière,…
Notice 2 : avec un titre de sous-partie
200 1#$aL’@Evolution des genres dans l’histoire de la littérature$h1$iIntroduction. L’évolution de la critique depuis la Renaissance jusqu’à nos jours$fFerdinand Brunetière
Une fois les regroupements effectués par les humains à partir des notices de l’échantillon, les données issues des tests ont été comparées et analysées avec celles de l’algorithme via un programme de comparaison automatisé réalisé en interne.
A suivre…
Ping : Expérimentation Sudoc FRBR II. L’évaluation : algo vs humain. 2/3 - OuBiPo
Ping : Expérimentation Sudoc FRBR II. L’évaluation : algo vs humain 3/3 - OuBiPo
Ping : PUC, Day 1 (8 septembre 2020) - OuBiPo
Ping : Le Permanent UNIMARC Committee et LRM, la suite (9 au 14 septembre) - OuBiPo
Ping : Veille 2020 - T4 - logiciels libres en bibliothèque, pratiques et actualité - BibLibre - Services et logiciels libres pour les bibliothèques - SIGB Koha, portail Bokeh, numérique, gestion