

Suite de :
Mais qu’est-ce qu’il se passe encore ? (1) Où en est l’expérimentation Sudoc FRBR ?
Des dysfonctionnements et une boîte noire
Force est de constater que les premiers résultats de l’expérimentation avec l’algoclc1 sont perfectibles. Le fichier partagé de signalement des anomalies par le réseau complète et consolide des éléments déjà pointés par l’Abes :
- 60% environ du signalement concerne des anomalies générées par l’algorithme
- 30% concerne un problème de catalogage
- les 10% restants sont un mélange des deux qu’il est parfois difficile de démêler.
L’actuelle clé de regroupement Titre Auteur (CLM) n’est donc pas toujours suffisante pour discriminer efficacement des notices devant appartenir – ou non – à une même grappe, censée représenter une œuvre (environ 56% des cas signalés sont dus à l’algorithme). Les valeurs de cette clé sont calculées à partir :
des 9 premiers caractères du 1er mot du titre
des 4 premiers caractères du 2ème mot du titre
des 2 premiers caractères du 3ème mot du titre
des 2 premiers caractères du 4ème mot du titre
du 1er caractère du 5ème mot du titre
des 4 premiers caractères du 1er mot du nom de l’auteur
Plusieurs cas de figure coexistent, les plus faciles à appréhender concernant le manque de caractères pris en compte dans le calcul des clés. Pour les titres, parfois la clé ne tient pas correctement compte des compléments de titres ou d’autres sous-zones suivant la sous-zone 200$a, tous les caractères ayant été “pris” avant de pouvoir atteindre des éléments discriminants.
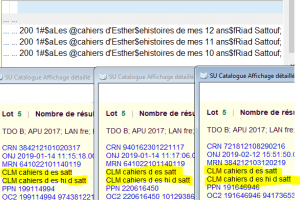
Des manuels scolaires ou des séries de bandes dessinées, parmi bien d’autres cas, peuvent ainsi être mal rassemblés. Comme ici par exemple, où trois tomes ne sont pas départagés par la génération des clés (une clé Titre Auteur avec la sous-zone $a et une autre avec les sous-zones $a et $e, toutes deux avec les 4 premières lettres du nom de l’auteur).
Par ailleurs, nombreux sont les exemples où des noms d’auteurs sont mal départagés car seuls les 4 premiers caractères du nom sont comptabilisés…
Ensuite, les problèmes d’affichage des noms d’auteurs en zone 579 sont un méli-mélo de l’algoclc1 qui gère mal des codes de fonction et a tendance à faire apparaître le nom d’auteur ayant le moins d’occurrences dans le regroupement. Mais de temps à autres, ce sont aussi des catalogueurs qui se mélangent les pinceaux avec de mauvais choix d’étiquettes dans le bloc des zones 7XX et/ou de codes de fonction dans certaines notices bibliographiques.
Il est important de rappeler que le soin apporté à la création, l’enrichissement et la correction des zones de liens 4XX, 5XX, 6XX et 7XX est essentiel pour la génération de regroupements pertinents et un affichage correct des données. L’algorithme est certes une aide pour les traitements de masse mais l’œil humain reste un atout majeur de la curation.
Après, il reste les cas épineux. Les notices d’agrégats (que l’on a fini par exclure des calculs) ou de livres anciens qui sont autant de pièges pour l’algorithme de par leurs spécificités.
Enfin, rappelons que la génération des clés elles-mêmes et la pondération appliquée par l’algorithme échappent totalement à l’Abes, seul le prestataire garde la main sur cette partie.
Un nouvel algo sort du chapeau !
Les principaux reproches faits à l’algoclc1 ont conduit à la rédaction de spécifications d’ajustement sur le contenu des notices de regroupement Tr. L’ajout de données supplémentaires pour mieux analyser leur origine, la fourniture de précisions sur le fonctionnement de la clé Titre Auteur pour affiner la sélection et la réduction du périmètre de calcul pour se focaliser sur les ressources signalées par les établissements.
Ces premières demandes ont été envoyées à OCLC en début d’été 2018, et là, coup de théâtre ! OCLC a développé un nouvel algorithme entre temps, appelons-le algoclc2. Ce nouvel algorithme est censé améliorer nativement un certain nombre d’anomalies pointées par les spécifications de l’Abes. Une nouvelle clé de comparaison plus précise, un nouveau mode de calcul et de pondération sont annoncés.
La confrontation des spécifications d’ajustement de l’algoclc1 aux améliorations apportées par l’algoclc2 oblige donc l’Abes à revoir sa copie et les négociations aboutissent à 7 demandes d’évolution qui portent sur 3 axes :
- le contenu des notices de regroupement Tr :
- ajout de la zone Unimarc 029
- ajout des identifiants (PPN) des notices de manifestation liées
- nettoyage des notices de regroupement des données issues des notices bibliographiques supprimées
- évolution du format des notices de regroupement Tr pour le bloc de zones 5XX et de la zone 579 dans les notices bibliographiques liées
- les modalités des calculs de regroupement :
- prise en compte des codes de fonction dans le résultat de l’algorithme de frbrisation
- exclusion des notices bibliographiques sans localisation pour le calcul des notices de regroupement Tr
- l’affichage : dans WinIBW, pour les notices d’autorité, affichage dans le mode UNM, du nombre de notices liées (soit le nombre que l’on obtiendrait si on lançait la commande « REL TT»). Le résultat est cliquable afin d’afficher la liste des notices liées à cette notice d’autorité.
Pour le moment, certains paramétrages demandés par l’Abes ont été mis de côté, algoclc2 étant, selon OCLC, suffisamment puissant pour s’en passer. Il s’agit de l’intégration d’une liste de mots vides et de la prise en compte de la zone Unimarc 105$bm des notices de thèses originelles pour forcer le système à les considérer comme des pré-notices d’œuvre.
Après la première phase de test, il sera normalement possible de juger de la pertinence d’ajouter ou non ces critères supplémentaires pour tenter d’améliorer des regroupements.
Et pour finir on recommence…
Plouf, plouf ! Aujourd’hui, on retourne à la case départ et on fait à nouveau le circuit en 3 temps :
- en mai, première phase de la recette de l’algoclc2 et des évolutions implémentées
- en juin et juillet, seconde phase de la recette avec la comparaison du fonctionnement de chaque algoclc puis l’ajustement des paramétrages si nécessaire. Un bilan d’étape sera réalisé en vue d’un passage en production à l’automne
- début 2020, une troisième phase de recette est prévue pour évaluer la pertinence de l’algoclc2 sur un échantillon de référence et tirer un bilan global de cette expérimentation.
L’exercice est particulièrement difficile pour l’Abes car les équipes techniques et fonctionnelles doivent travailler sous contrainte forte. Pendant les deux premières phases de la recette, 2 personnes (0,7 ETP environ) vont être fortement mobilisées, sans filet de sécurité car l’Abes n’est pas en mesure d’engager des forces supplémentaires. Contrainte de calendrier ensuite : pendant ces deux mêmes phases qui vont durer quelques mois, OCLC ne peut pas synchroniser automatiquement les tables de paramétrages de la base de production du Sudoc avec celles de la base de test (impactées par l’expérimentation Sudoc FRBR). Toute évolution du format Unimarc est ainsi gelée pendant plusieurs mois du fait de l’expérimentation Sudoc FRBR, ce qui n’est pas anodin pour les chantiers parallèles de la Transition bibliographique.
Pendant ce temps, remettons-nous de nos émotions en écoutant le “Grand Jacques” nous raconter comment naît une de ses œuvres (pour les plus pressés allez directement à la minute 3’48’’).
Bonjour,
Merci encore pour votre communication qui nous permet de mesurer le poids de ces changements et de ce qu’ils entraînent : choses qu’il ne nous aie pas toujours aisé de mesurer (mais s’il est long d’écrire une chanson alors réécrire un applicatif lié à une nouvelle « norme » … !!)
Tenez bon ! … pour nous !
Vos encouragements boostent notre motivation ♡
Ping : Expérimentation Sudoc FRBR II. Portrait robot d’un algo - OuBiPo