Comment le rapport van der Graaf a-t-il nourri les réflexions de l’Abes ?
La commande d’un rapport sur les implications concrètes de la Transition bibliographique dans l’ESR constituait la première réponse de l’Abes aux demandes formulées en 2022 tant par le Ministère de l’enseignement supérieur et de la recherche que par l’Hcéres dans son rapport d’évaluation de l’Abes, qui exprimaient tous deux la nécessité que l’agence clarifie sa trajectoire vers la transition bibliographique.
L’Abes s’est approprié les éléments fournis par le rapport de Mauritz van des Graaf dans le cadre de sa réflexion sur son Projet d’établissement 2024-2028, et les a également portés au niveau national, pour discussion au sein du Comité stratégique bibliographique (CSB), qui chapeaute le programme Transition bibliographique.
Le projet d’établissement 2024-2028 de l’Abes prend en compte l’importance du renouvellement technologique en œuvre à l’échelle internationale. S’il place en toute première priorité – et sur un temps long – la refonte du système de gestion des métadonnées de l’Abes (le Sudoc et ses applications satellites) du fait de son obsolescence technique et prévoit un investissement important pour mener à bien ce projet, des réalisations concrètes à moyen terme auront bien lieu, avec acquis progressif :
un premier déploiement du nouveau système remplaçant l’interface professionnelle de catalogage WinIBW et l’interface publique du Sudoc (PSI) en 2027
une interface expérimentale de visualisation des entités et relations issues du Sudoc également avant la fin de la période, quel que soit le modèle conceptuel qui sous-tendra les données dans le nouveau système de gestion
Cette façon de faire devrait permettre de s’adapter, au fil des années, aux évolutions en cours dans le paysage des standards comme dans celui des SGB, et d’en tirer le meilleur parti.
Parmi les suites du rapport de Maurits Van Der Graaf, une discussion nationale a eu lieu le 18 octobre, dans le cadre du Comité stratégique bibliographique (CSB). Il s’agissait de tirer les conclusions de l’analyse présentée dans le rapport pour la trajectoire du programme national Transition bibliographique.
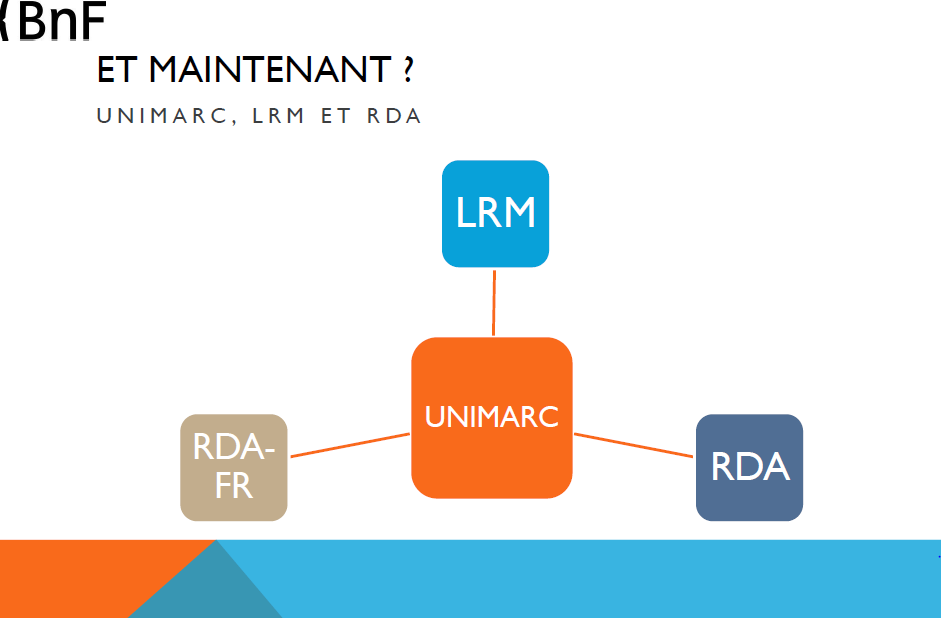
Établie en 2014 autour de la nécessité de développer RDA-FR en tant que code de catalogage national et de sensibiliser la communauté documentaire aux enjeux associés à la modélisation entités-relations, la feuille de route initiale du programme n’avait jamais connu d’actualisation. Dans les faits, depuis 2014, cette trajectoire nationale s’est fixée sur un double principe :
le remplacement des normes de catalogage anciennes (AFNOR Z44-…) par le standard RDA-FR basé sur le modèle entités-relations international IFLA LRM
l’adaptation du format d’échange de données national, d’UNIMARC vers UNIMARC entités-relations.
Le rapport de Maurits Van Der Graaf fait apparaître, en creux, certaines limites que pose cette trajectoire pour l’écosystème de l’ESR, très fortement dépendant des développements internationaux en ce qui concerne, d’une part, le marché des logiciels documentaires utilisés par les établissements (SGB, outils de découverte, etc.) et, d’autre part, les flux de données que l’Abes met à disposition des réseaux de catalogueurs pour faciliter la description des ressources dans le Sudoc.
BIBFRAME (de l’anglais Bibliographic Framework) est à la fois un modèle de données de description bibliographique, un format et un vocabulaire. Il a été conçu par la Bibliothèque du Congrès pour remplacer le format MARC en se basant sur le Web de données afin de rendre les bases de données bibliographiques plus accessibles aux usagers, aussi bien dans que hors les murs des bibliothèques. (source : page Wikipédia Bibliographic Framework)
De MARC à BIBFRAME
En 2012, à la suite d’un rapport interne (paru 4 ans plus tôt) sur le futur du catalogage, qui constatait l’obsolescence technologique du MARC et son usage restreint à la communauté des bibliothèques, la Bibliothèque du Congrès développe avec le prestataire Zepheira un modèle de description et un vocabulaire basé sur le standard RDF. Cette initiative, appelée BIBFRAME, permet de décrire les ressources des bibliothèques en respectant des principes également promus par le modèle FRBR de l’IFLA (qui deviendra IFLA LRM en 2017) :
distinguer le contenu conceptuel d’un document, et sa matérialisation physique ou numérique
identifier les entités permettant de décrire la ressource et de la contextualiser (par exemple, les agents, les sujets)
relier les entités entre elles en utilisant leurs identifiants contrôlés.
à noter : Si ces principes étaient déjà présents dans le MARC21 (et à plus forte raison dans l’UNIMARC), ils étaient considérés comme l’exception dans les pratiques de catalogage, et non comme la norme (source : BIBFRAME Frequently asked questions).
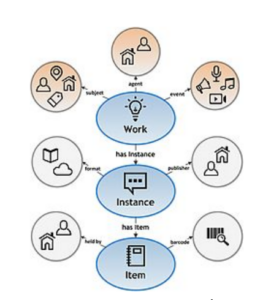
Le modèle BIBFRAME comprend 3 entités principales :
Work : il s’agit de l’essence conceptuelle d’une ressource (auteurs, langues, sujets)
Instance : elle reflète l’incarnation matérielle d’une ressource (éditeur, date de publication, format).
Item : il s’agit d’une copie réelle (physique ou électronique) d’une instance (localisation physique ou virtuelle, cote, code-barres).
BIBFRAME 2.0 (2016) : schéma conceptuel
Bien que l’on puisse considérer que le niveau “Work” dans BIBFRAME (bf:Work) est proche de l’entité “Expression” dans IFLA LRM, celles et ceux qui connaissent le modèle IFLA LRM voient tout de suite que ces deux modèles ne semblent pas compatibles. Certains établissements ayant implémenté BIBFRAME ont donc travaillé sur un niveau supplémentaire, le “Hub” (bf:Hub), qui correspond peu ou proue à l’entité “Oeuvre” du modèle IFLA LRM. Cependant, ces alignements ne sont pas si simples et la communauté BIBFRAME continue de travailler sur l’articulation entre les modèles BIBFRAME et LRM, qui est un modèle international publié sous l’égide de l’IFLA, ce que n’est pas BIBFRAME.
Modèle, code, norme et format … Et si on s’expliquait ?
Pour bien comprendre ce dont on parle lorsqu’on évoque la transition bibliographique, il faut bien connaître les différents concepts. Ce billet propose :
une définition des concepts suivants : “modèle conceptuel”, « norme”, “code de catalogage” et “format”
la description des liens qui existent entre eux.
Qu’est ce qu’un modèle conceptuel, une norme, un code de catalogage ?
Avant de définir ces concepts, faisons un parallèle avec un exemple que tout le monde connaît : le jeu de tennis.
Djokovic au service (source : Mad Ball from Flickr)
Si trois personnes devaient expliquer à une quatrième ce qu’est le tennis, la première personne pourrait commencer par dire : “Le tennis est un sport, qui consiste à se renvoyer une balle, entre deux joueurs, et à inciter l’adversaire à commettre une faute, pour emporter le point”
Puis, la deuxième pourrait préciser : “ On y joue sur un terrain qui s’appelle un “court”, il est rectangulaire, il mesure 23,77 m. de longueur pour 8,23 m. de largeur. La dimension de la balle doit avoir un diamètre compris entre 6,35 et 6.66 cm”.
Enfin, la troisième pourrait ajouter : “Si la balle atterrit hors des limites du court, le point est perdu ; si la balle touche le filet lors du service, on rejoue” .
À elles trois, ces personnes ont décrit le même sport, chacune sous des angles différents, mais complémentaires. La première personne a donné la définition, unique et universelle, du jeu de tennis. Partout dans le monde, cette définition s’applique. C’est un modèle conceptuel. La deuxième personne a donné des éléments techniques et pratiques à respecter pour que le jeu se joue de façon identique, partout et tout le temps. Ce sont des normes. La troisième personne a détaillé comment, dans le cadre de la définition donnée et au moyen des éléments techniques à respecter, chacun doit se comporter. Ce sont les règles du jeu, autrement dit le code.
Cette étude, menée de manière indépendante et neutre, a été demandée dans l’objectif d’aider l’Abes à définir, pour elle et pour ses réseaux, une trajectoire pragmatique et réaliste dans la mise en œuvre des transformations induites par la transition bibliographique. Entamé depuis plus de 8 ans, le programme national Transition bibliographique, co-piloté par l’Abes et la BnF, doit désormais trouver une application concrète au sein des réseaux de l’ESR. Dans la perspective de son prochain Projet d’établissement 2024-2028, l’Abes doit se doter d’une vision claire et réaliste des modalités de transformation de ses catalogues et bases de données, étayée des retours d’expériences internationaux ou français, à dessein de mieux mesurer les risques, d’anticiper les coûts et de préparer la communauté des bibliothécaires de l’ESR à ces changements majeurs.
Le passage à un système de données organisé selon une modélisation entités-relations, entièrement compatible avec les principes du Linked data, fait partie des axes de travail de l’agence pour les prochaines années. Mais comment la mettre en œuvre concrètement, et comment l’articuler étroitement avec la refonte du système d’information documentaire de l’Abes, aujourd’hui vieillissant, tout en accompagnant les réseaux dans cette évolution si importante ?
De ce rapport étaient attendues une analyse des mises en œuvre déjà existantes et des propositions pour aider à dessiner la trajectoire des prochaines années.
Une mise en perspective internationale
Dans le cadre de son rapport, Maurits Van der Graaf a interrogé de nombreux professionnels des bibliothèques au niveau international (Belgique, Suisse, Pays-Bas, Slovénie, Allemagne, Suède, Norvège, Finlande, Royaume-Uni, États-Unis), ainsi que des représentants de fournisseurs de métadonnées et d’éditeurs de SGB très représentés dans les bibliothèques de l’ESR.
Il a ainsi pu caractériser la tendance qui se dessine dans les grands projets internationaux de SI de nouvelle génération : le modèle et vocabulaire BIBFRAME, initialement conçu en 2011 par la Bibliothèque du Congrès, est actuellement en fort développement et connaît une adoption de plus en plus large dans des projets visant à diffuser des données MARC dans un univers Linked Data, voire à produire directement des données compatibles, sans conversion, avec les standards du Linked Data. À noter toutefois qu’un des inconvénients actuels de ce modèle non normalisé est sa libre adaptation au gré des besoins et contraintes de ses utilisateurs, avec les inconvénients que suscitent ces adaptations dans l’échange de données bibliographiques.
Depuis les réunions annuelles en visio de 2020, il n’y a pas eu de billet Oubipo sur le PUC (Permanent UNIMARC Committee), l’organe international de maintenance du format UNIMARC sous l’égide de l’IFLA. Que devient le PUC, vous demandez-vous peut-être … mais également : que devient le format UNIMARC ?
Eh bien, le PUC se réunit toujours en visio, une fois l’an au printemps, pendant quelques demi-journées. Il comporte une dizaine de membres issus majoritairement de pays d’Europe (Croatie, France, Grèce, Lituanie, Portugal, Slovénie) mais aussi de Russie et d’Iran, et une représentante d’OCLC. La présidente, Gordana Mazić, est slovène. La France est représentée par Héloïse Lecomte (Abes), en tant que pilote du Comité français UNIMARC (CfU).
La France, moteur des évolutions du format UNIMARC
Que se passe-t-il lors des réunions annuelles du PUC ? On y débat des évolutions du format d’échange proposées par les membres du comité, et on y suit les autres projets de l’IFLA impliquant le format UNIMARC.
Notons que, depuis 2020, la France est le seul pays à avoir fait des propositions d’évolution du format. Cette année, par exemple :
Une proposition française a abouti à la validation d’un ensemble important de zones dédiées au catalogage en UNIMARC/B des monnaies et médailles, présentées une première fois lors des réunions du PUC 2022 par Florence Tfibel (BnF). Un guide de bonnes pratiques préparé par nos collègues de la BnF devrait être publié sur le site de l’IFLA pour accompagner ces nouvelles zones, l’ensemble étant attendu pour cet automne.
La discussion sur la généralisation d’une sous-zone dédiée aux URI a abouti, sur la base de propositions françaises formulées dans un discussion paper en 2022 : la « sous-zone de contrôle » $3 (comprenez : sous-zone applicable de la même façon dans tout le format) permettra dorénavant d’enregistrer des URI pointant vers des descriptions d’entités, et plus seulement des identifiants système. C’est une étape supplémentaire vers des données liées.
La France a également présenté 15 propositions d’évolution allant de la définition d’un référentiel à la création d’une nouvelle sous-zone ou zone, pour améliorer le format UNIMARC dédié au catalogage entités-relations (« UNIMARC ER », parfois aussi appelé « UNIMARC-LRM »). Des manques ou incohérences avaient en effet été constatés par le groupe de travail qui a créé et publié fin 2022 un jeu de notices OEMI en UNIMARC ER sur la plate-forme Zenodo du programme Transition bibliographique.
6 de ces propositions ont été acceptées,
9 doivent être retravaillées et seront débattues de nouveau lors d’une réunion de suivi.
Pendant ce temps, les collègues slovènes travaillent sur la prochaine édition complète des manuels UNIMARC A et B, qui sera disponible intégralement et gratuitement en ligne, et certains membres du PUC participent à des groupes de travail sur la création d’une ontologie pour l’UNIMARC/A (celle pour l’UNIMARC/B existe déjà), ou sur l’évolution de l’ISBD dans un contexte de catalogage par entités, conforme au modèle LRM.
Depuis décembre 2021, l’Abes a mis en place une équipe transversale dédiée à l’amélioration de la qualité des données Sudoc en vue de leur « LRMisation », c’est à dire de leur migration à moyen terme vers une structure compatible avec le modèle IFLA-LRM et le code de catalogage RDA-FR.
Ces travaux s’inscrivent dans la suite de l’expérimentation « Sudoc FrBr » menée de 2014 à 2021.
En savoir plus sur le processus : consulter le diaporama de la session plénière des Journées Abes 2021 – « Repenser le SI de l’Abes en période de transition(s) ».
En savoir plus sur l’expérimentation « Sudoc FrBr » : consulter ces billets de blog.
Quelle est l’activité de cette équipe ?
L’équipe « Qualité/corrections LRM », constituée de 9 membres issus des différents services du département Métadonnées et Services aux Réseaux (DMSR), a initié plusieurs chantiers de corrections portant sur des lots de notices ayant des caractéristiques communes.
Les premiers chantiers, menés depuis la mi-décembre, ont porté sur les notices comportant des erreurs empêchant de les modifier (par exemple : incohérence entre le type de document – imprimé ou électronique – et les zones présentes – B135, B856…), ce qui permet notamment de repérer des notices dont le support est mal renseigné (papier > électronique, ou inversement). Des erreurs bloquantes ont ainsi pu être corrigées à ce jour dans près de 75 000 notices.
D’autres chantiers de ce type sont en cours à l’issue desquels l’équipe se concentrera sur l’amélioration des zones clés pour la LRMisation des données : données codées, zones de titres, de responsabilité, etc.
Organisée en ligne pour la première fois, sur le thème « Cataloguer par entités ou le big bang des données« , la 5ème journée professionnelle « Métadonnées en bibliothèque » organisée par le groupe « Systèmes et Données » du programme national Transition Bibliographique a réuni près de 500 participants.
Les enregistrements des présentations sont à consulter ICI.
Avec l’intervention « Décrire les œuvres et les expressions« , par Héloïse Lecomte (Abes) et Florence Tfibel (BnF), on découvre comment les évolutions du format UNIMARC (validées par le PUC) permettent désormais de traduire en format les éléments constitutifs des entités Œuvre et Expression. Ces évolutions majeures, outre le fait qu’elles aident à mieux comprendre le contour de ces entités, vont permettre de travailler de manière concrète à l’évolution des logiciels, l’éclatement des notices, la reprise des données, la mise en place de nouveaux outils de production…
L’intervention « Transformation d’une notice en arbre OEMI » par Tiphaine-Cécile Foucher (BnF) illustre ce que signifie « cataloguer par entités » : on y voit comment les données d’une notice bibliographique du catalogue général de la BnF sont redistribuées dans les nouvelles entités de l’arbre OEMI (OEuvre Expression Manifestation Item).
Les catalogueurs ont également été informés des avancées du « Projet FNE« , futur outil de production d’entités, par Anila Angjeli (BnF) et Benjamin Bober (Abes).
Ces orientations doivent se matérialiser dans les systèmes de gestion des bibliothèques. Grâce aux retours d’expériences (partie 5) des bibliothèques ayant commencé la transformation de leur catalogue, elles sont apparues plus concrètes. Chaque catalogueur peut ainsi mesurer le chemin parcouru, et réaliser que la transition bibliographique est en marche.
« Cataloguer par entités ou le big bang des données » (Image par Gerd Altmann de Pixabay)
Lors des sessions du Permanent UNIMARC Committee 2020, l’essentiel des discussions a été consacré à l’adaptation du format au modèle LRM à travers la finalisation des grilles de description des œuvres et expressions dans le format UNIMARC/A. Consulter les billets précédents :
Après le marathon de septembre, les membres du PUC ont eu le plaisir de se retrouver du 19 au 22 octobre pour 3 autres réunions au cours desquelles ont été débattues quelques autres évolutions des formats UNIMARC/A et B.
Voici un éclairage sur les principales décisions prises, en attendant la publication officielle des mises à jour 2020 du format UNIMARC sur le site de l’IFLA et la mise en œuvre de certaines de ces nouveautés dans le Sudoc, selon un calendrier et des modalités à définir. N’hésitez pas à nous signaler des besoins en la matière !
Une amélioration de la zone B225 pour les ensembles monographiques
La représentante de la Bibliothèque nationale de Russie a proposé la correction d’une lacune dans la zone B225, correspondant à la « zone de la collection et de la monographie en plusieurs volumes » de l’ISBD et permettant de transcrire le titre, les compléments de titre et les mentions de responsabilité de la collection ou de l’ensemble monographique dans lequel se situe une ressource. Il sera désormais possible d’indiquer l’ISBN, l’ISMN (identifiant des partitions) ou tout identifiant international de l’ensemble monographique dans la nouvelle sous-zone $y.
Par exemple, dans la notice bibliographique du 1er volume de l’ensemble The History of Chinese Civilization, l’ISBN de l’ensemble (1-107-01309-7) pourra désormais être catalogué en B225 $y, tandis que l’ISBN du volume restera enregistré dans la zone 010.
De nouveaux codes pour des alphabets très utilisés
Prenant acte du petit nombre de codes d’écriture proposé par le référentiel UNIMARC utilisé par les catalogueurs pour la zone B100 (positions 34-35, « écriture du titre ») et la sous-zone de contrôle $7 du format autorités (positions 0-1, « écriture de catalogage » et 4-5 « écriture de la racine de la vedette » – la traduction française n’ayant pas encore été remise au goût du jour…), la représentante de l’ICCU, agence bibliographique nationale italienne, a fait la proposition d’ajouter des codes pour une meilleure représentation d’alphabets non latins dans les notices en UNIMARC. En effet, pour le moment, les catalogueurs ne peuvent utiliser que le code « zz – autre » pour ces écritures, qui demeurent donc invisibles dans les données structurées de nos catalogues.
Petit manuel scolaire birman, collection de la BULAC – Source
Le critère choisi par les italiens est celui du nombre de locuteurs des langues utilisant ces alphabets : un nouveau code a été proposé pour toutes les écritures utilisées actuellement par au moins 10 millions de personnes dans le monde. Si cette méthodologie peut sembler arbitraire en ne se fondant pas sur les besoins de description réels des bibliothèques utilisatrices de l’UNIMARC, qui ont été jugés trop difficiles à recenser, elle a le mérite d’être objective.
Les nouveaux codes correspondent presque uniquement à des écritures asiatiques : birman, khmer, bengali, gujarati, gurmukhi, odia, kannada, malayalam, cingalais, telugu. Un code représentera également l’alphabet éthiopien. D’autres écritures pourront bien sûr être intégrées à cette liste de codes en fonction des besoins signalés par les communautés utilisant l’UNIMARC.
La question de l’utilisation de la norme ISO 15924 plutôt que de la liste UNIMARC pour représenter les codes d’écriture a été posée par la France. En effet, la norme ISO est complète : représentant toutes les écritures du monde, elle est maintenue par une instance ad hoc. La présidente du PUC a proposé que les représentants nationaux interrogent les bibliothécaires et les fournisseurs de SGB de leurs pays afin de vérifier l’intérêt et la faisabilité technique de cette évolution, les codes ISO ayant 4 caractères (et non 2 comme les codes UNIMARC). Le sujet sera à l’ordre du jour du PUC 2021.
De nouveaux codes de fonction en provenance d’Italie
Cette année, les collègues italiens ont également planché sur les codes de fonction (utilisés en B/7XX $4 pour indiquer le rôle joué par un agent en relation avec une ressource), en particulier dans le domaine des manuscrits et du livre ancien.
Page de titre de Summaire ou Epitome du livre de Asse de Guillaume Budé (1523) – Source
Voici les nouveaux codes retenus :
355 – Epitomateur (du grec ἐπιτομή, epitomē) : personne qui compose l’abrégé d’une œuvre. Ce code sera utile en particulier lorsqu’une œuvre antique n’est connue que par son épitomé.
407 – Glossateur : auteur de gloses. Ce code est plus spécifique que « 212 – auteur du commentaire ».
552 – Notaire : cette fonction est utile dans le cadre de la description de matériaux archivistiques et/ou de manuscrits.
678 – Restaurateur : même type d’utilisation.
735 – Translittérateur : utile uniquement dans le cas de textes anciens manuscrits, qui nous sont parvenus via une translittération faite par une auteur plus tardif.
Enfin, dans le domaine du jeu, un nouveau code, plus spécifique que l’actuel « 245 – Concepteur », a été défini : « 405 – Concepteur du jeu (Game designer) »
Les échanges qui se sont déroulés sur 5 jours sont évoqués dans 2 billets distincts.
1.« PUC , Day 1 » 2. « Le Permanent UNIMARC Committee et LRM, la suite (9 au 14 septembre 2020) » (ce billet)
Après la séance d’ouverture de la réunion annuelle du Permanent UNIMARC Committee, les 4 journées suivantes ont été consacrées à l’examen des propositions d’évolution du format bibliographique et du format autorités. La France portait de nombreuses demandes, concernant principalement le format autorités. Il s’agissait de le compléter pour lui permettre d’exprimer l’ensemble des attributs des entités « Œuvre » et « Expression » prévues par le modèle IFLA-LRM.
Extrait du diaporama de F. Tfibel (BnF) présenté lors de la Journée « Systèmes & Données » le 15/11/2019
De RDA-FR à UNIMARC en passant par LRM
Initiée par les collègues du département des Métadonnées de la BnF, la comparaison entre les attributs des œuvres et expressions dans RDA-FR (voir RDA-FR, section 2) et l’état actuel du format UNIMARC a abouti à plusieurs constats :
En poursuivant votre navigation, vous acceptez le dépôt de cookies tiers destinés à vous proposer des vidéos, des boutons de partage et des remontées de contenus de plateformes sociales.J'accepteNon, merciEn savoir plus




![Page de titre de Summaire ou Epitome du livre de Asse […] de Guillaume Budé (1523)](https://oubipo.abes.fr/wp-content/uploads/2020/11/italie-198x300.jpg)